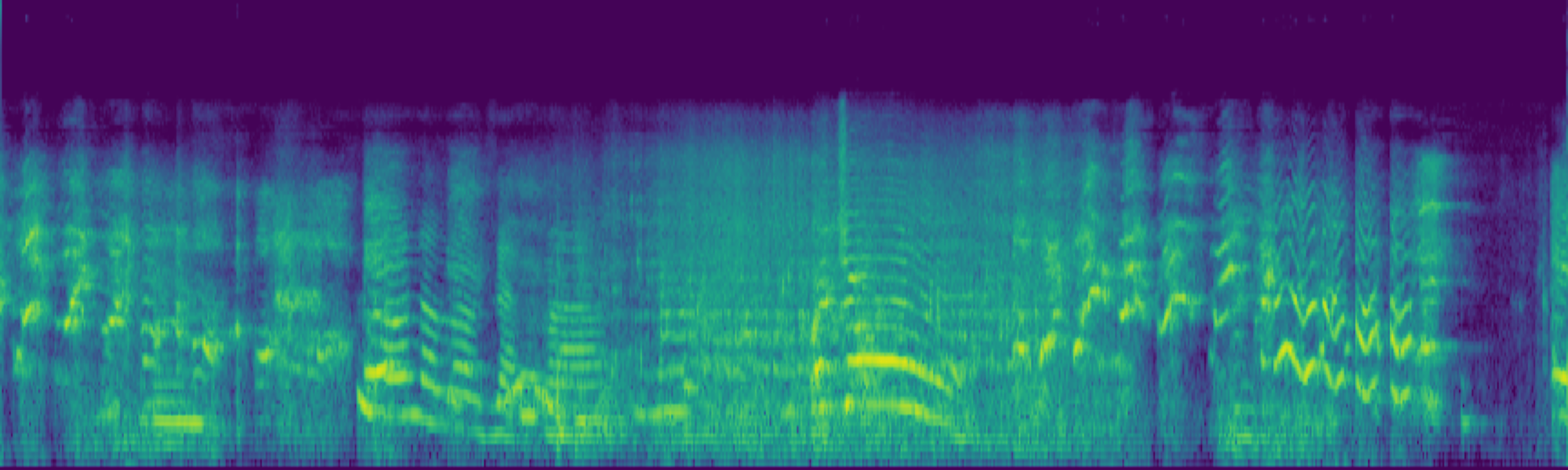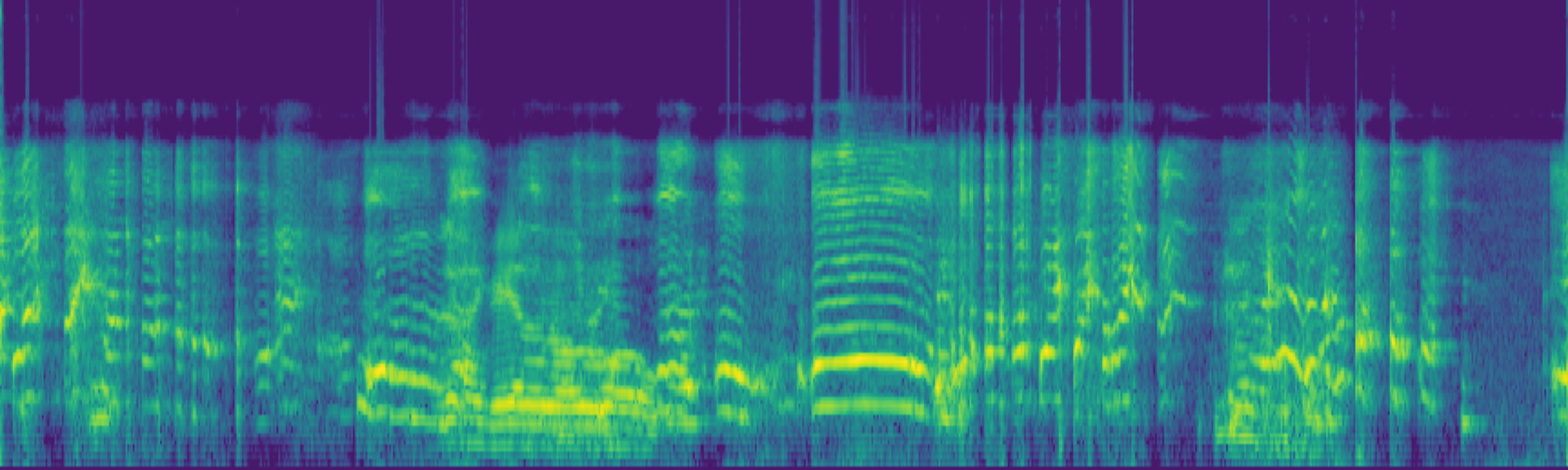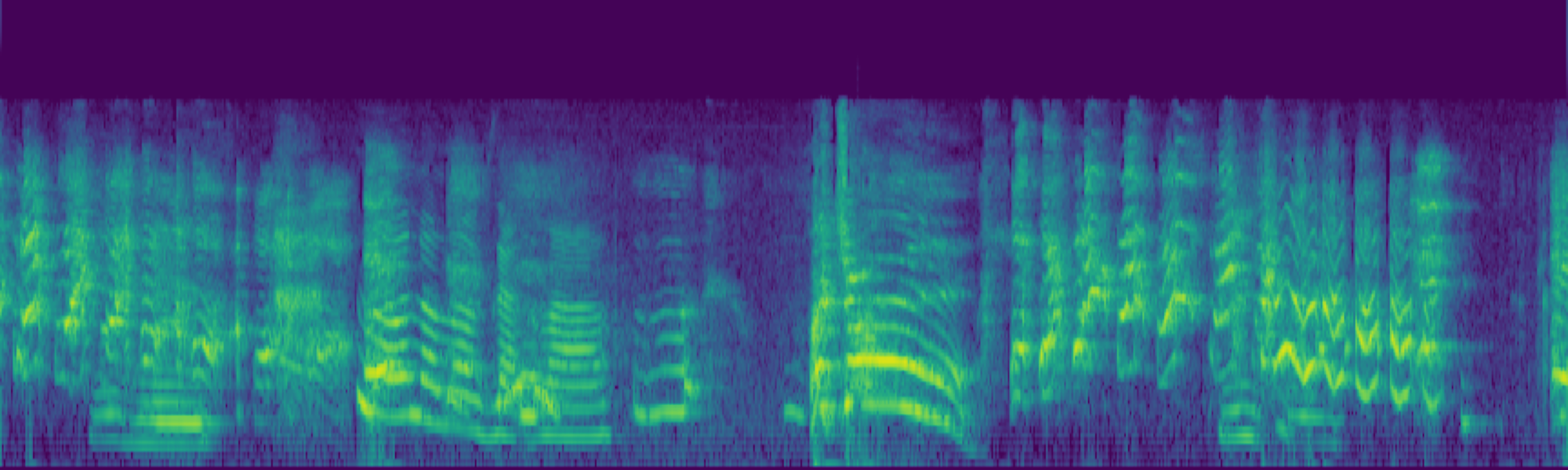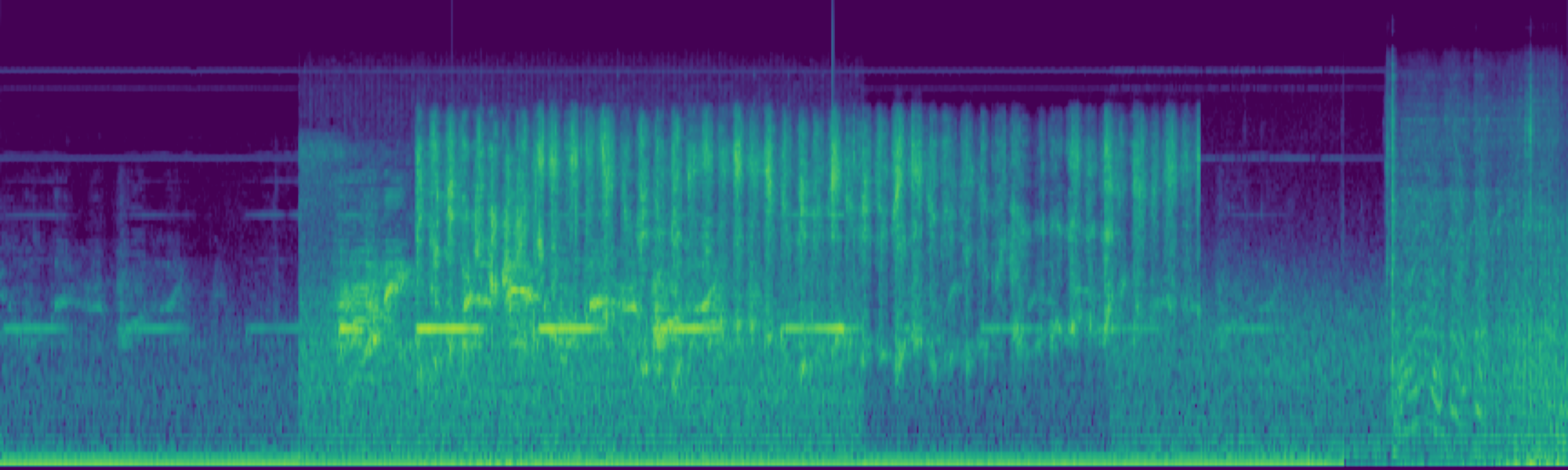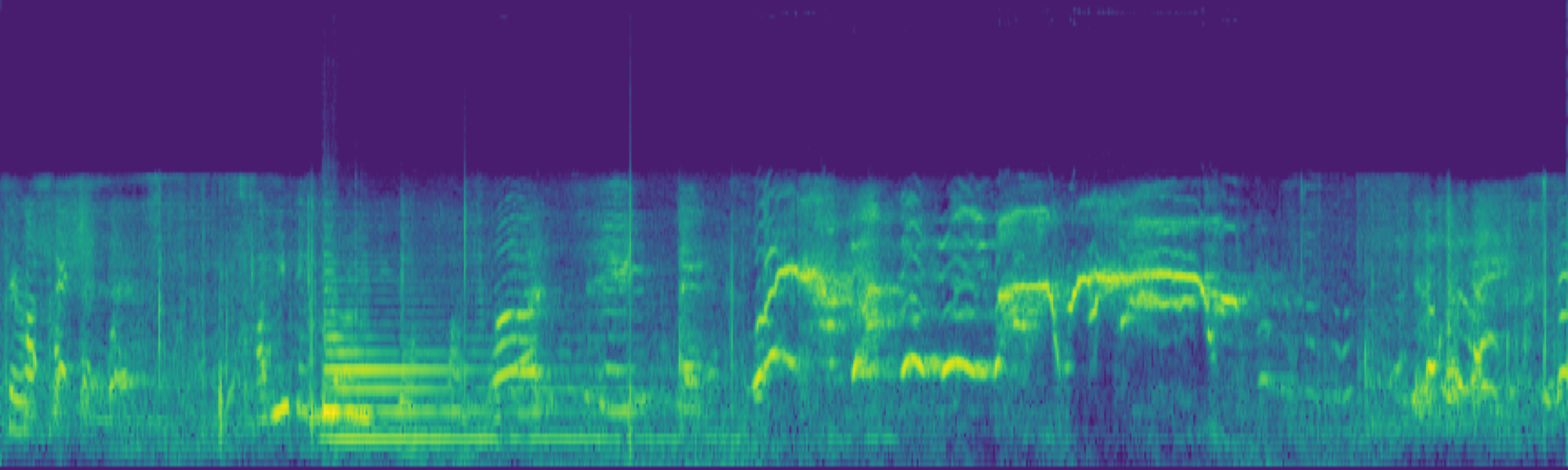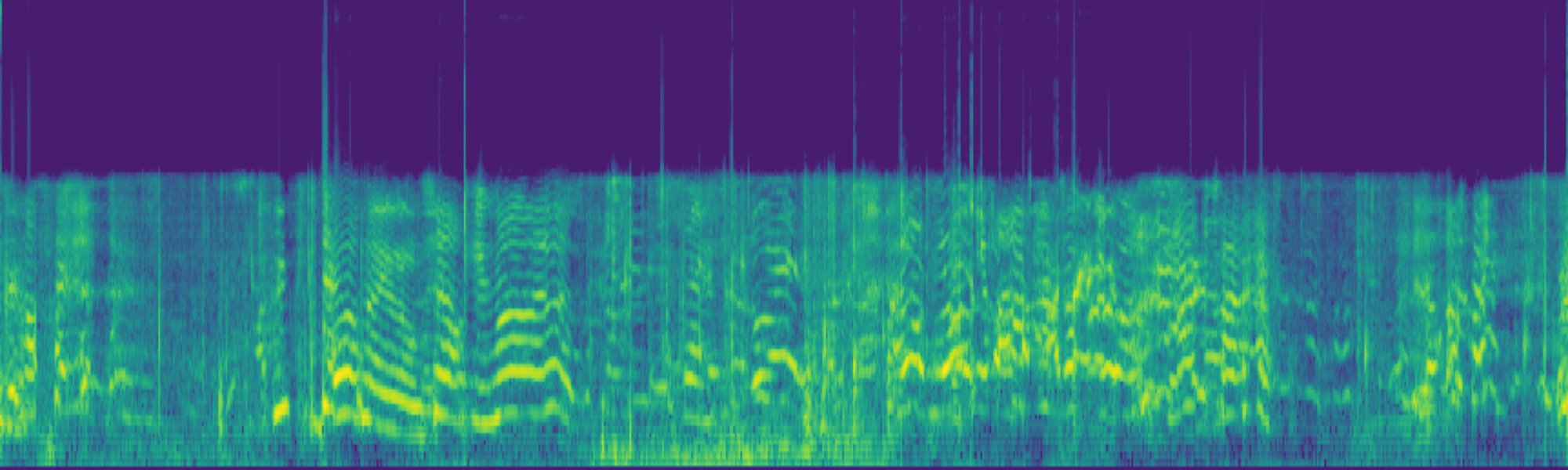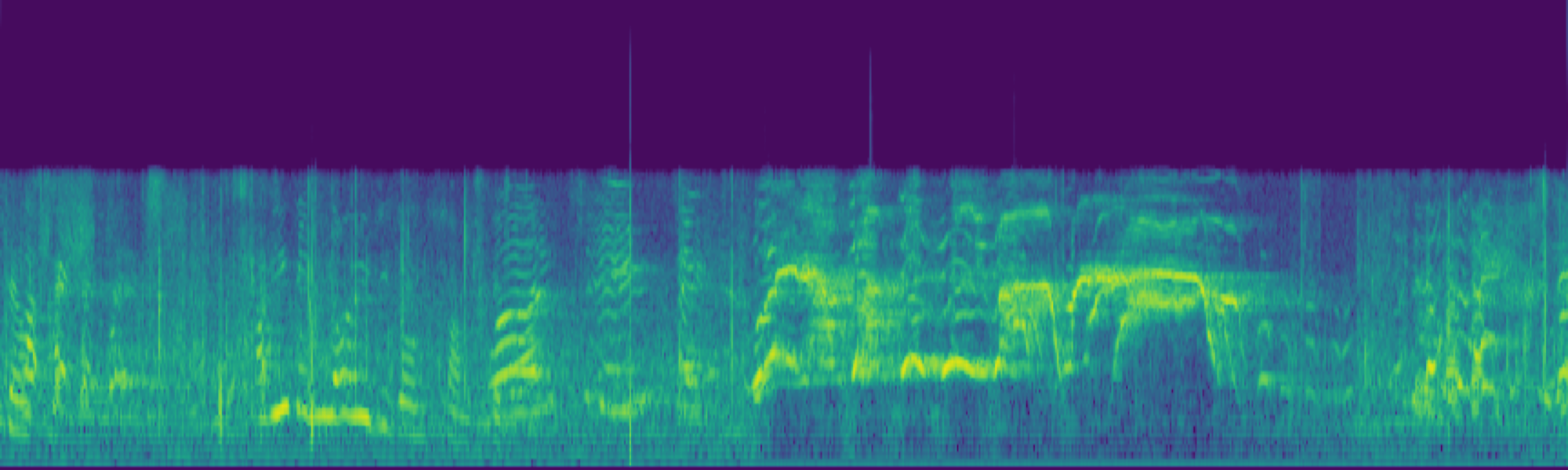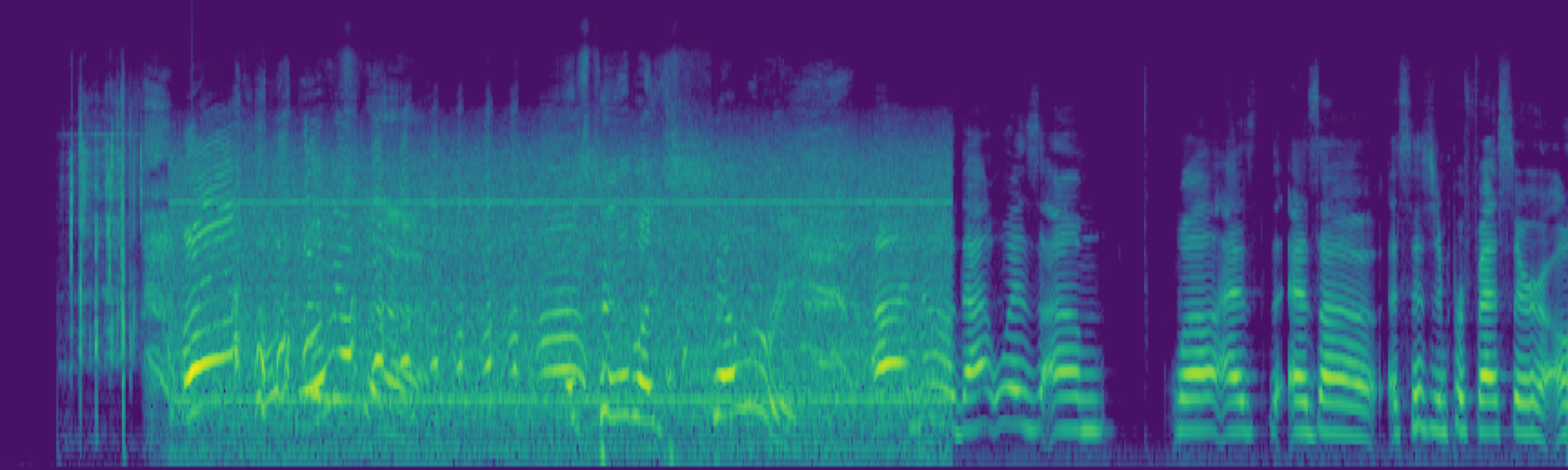
Abstract
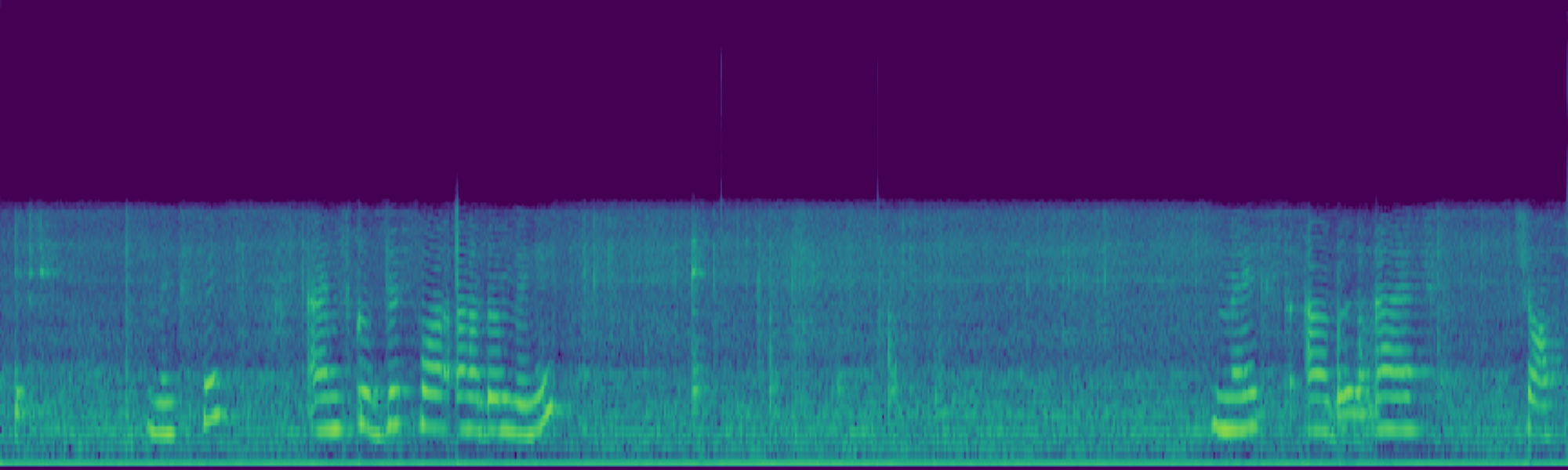
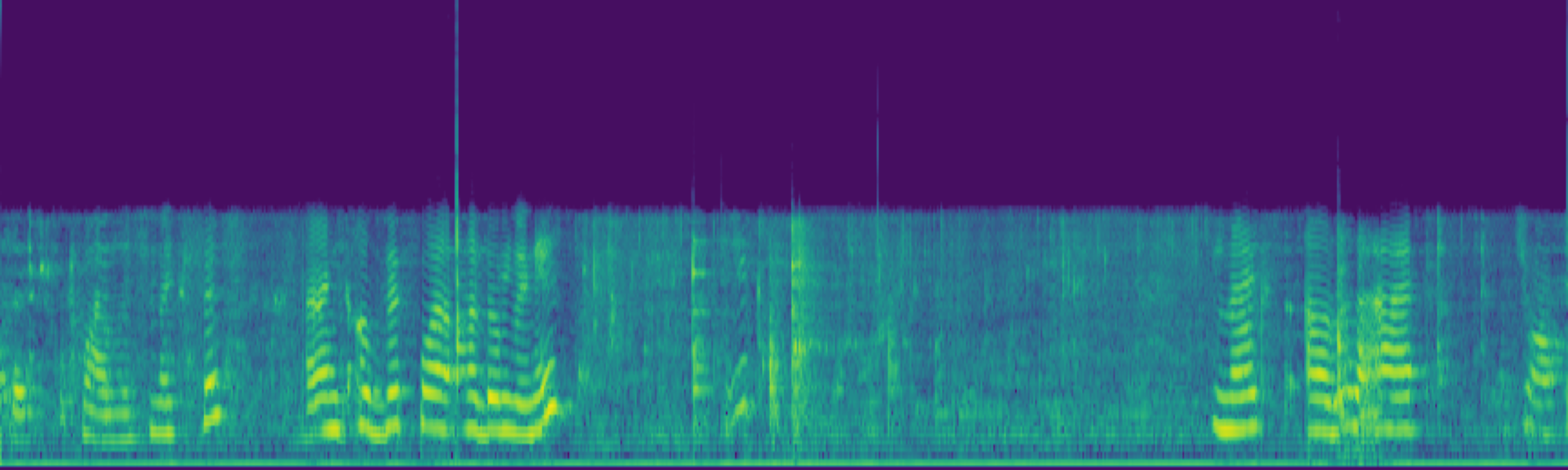
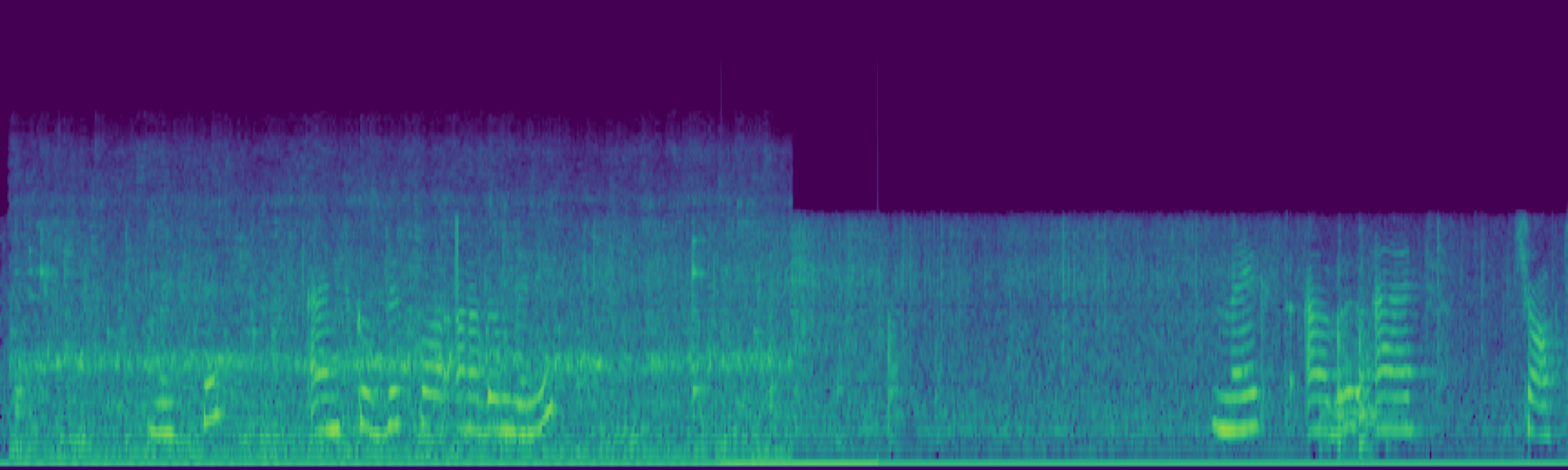
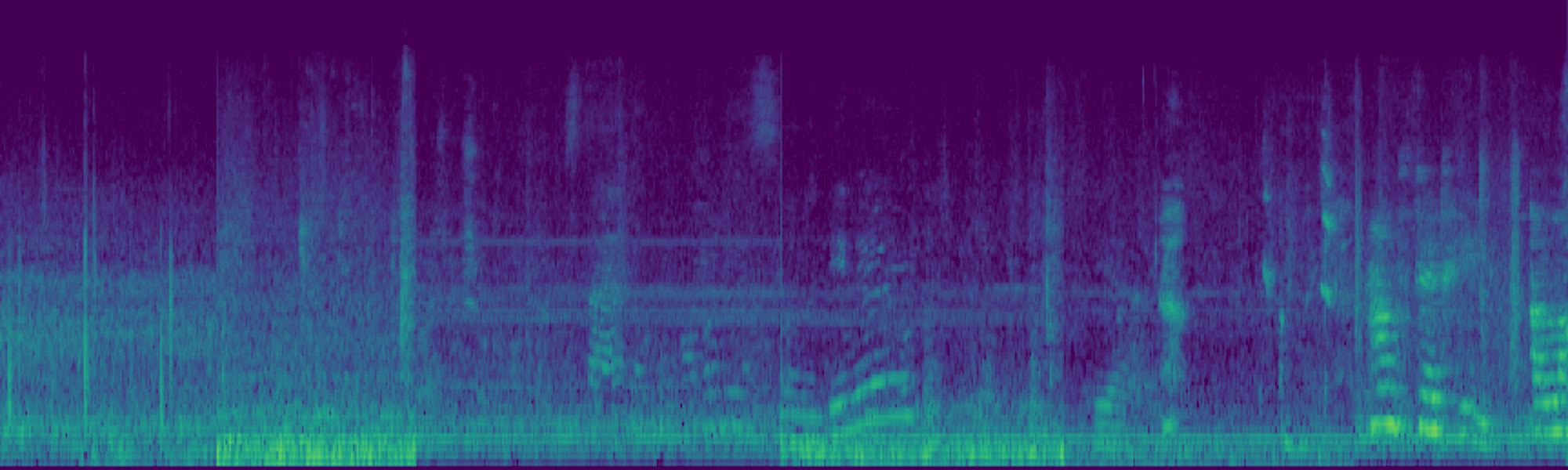
Text-to-audio (TTA) generation has made significant strides, yet achieving precise and consistent audio editing remains a major challenge. Existing methods often struggle to balance temporal consistency with background preservation, frequently failing to isolate modifications from the original acoustic context.
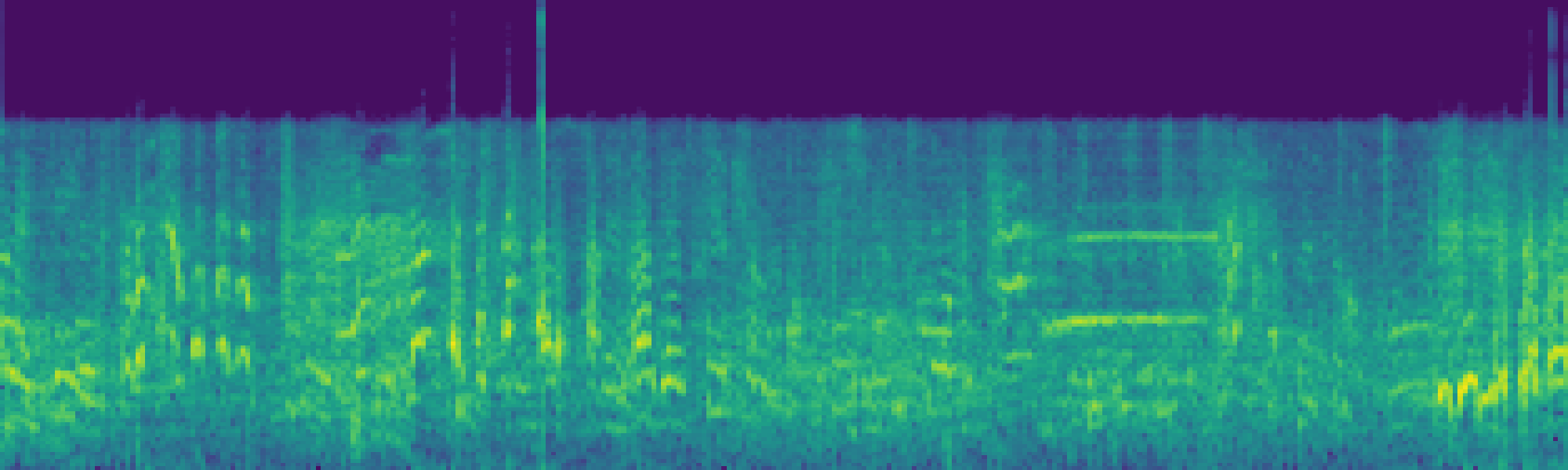
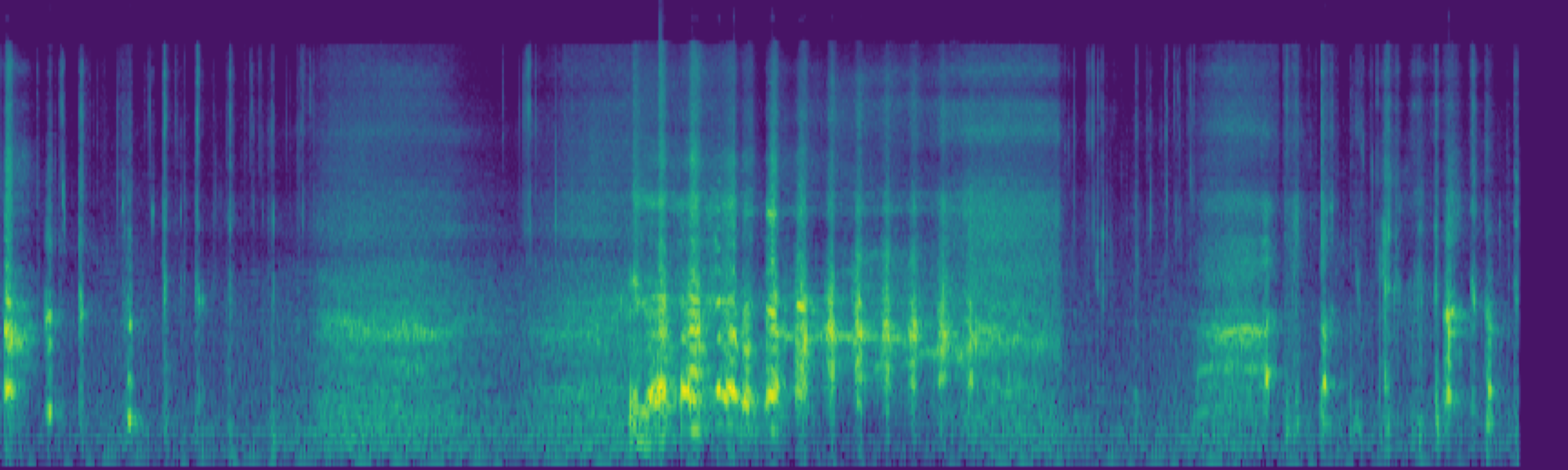
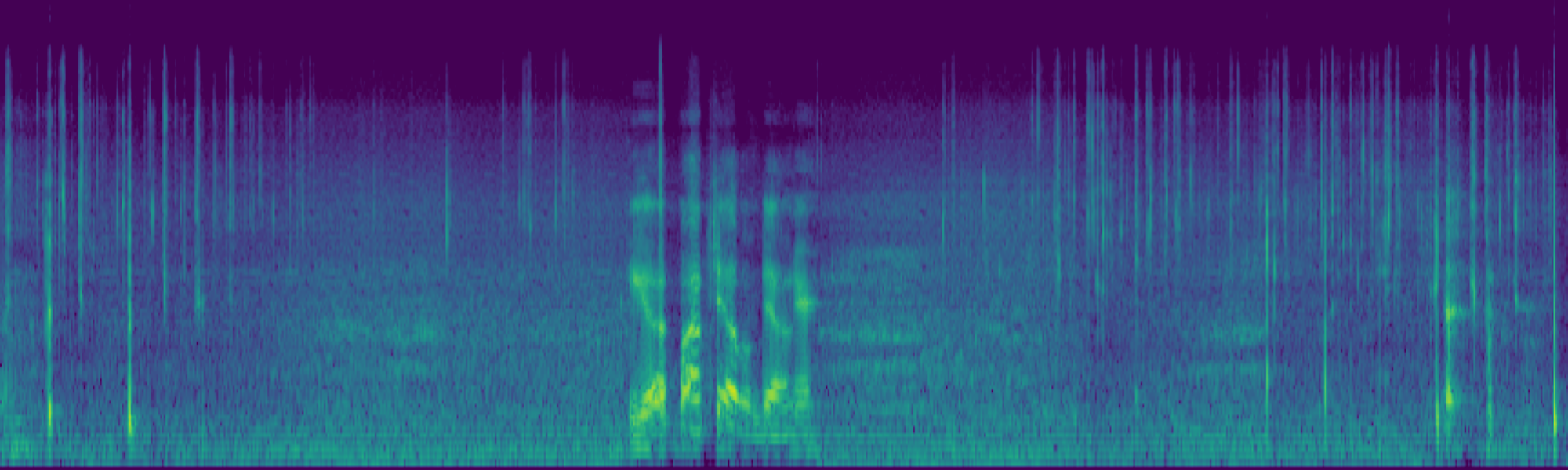
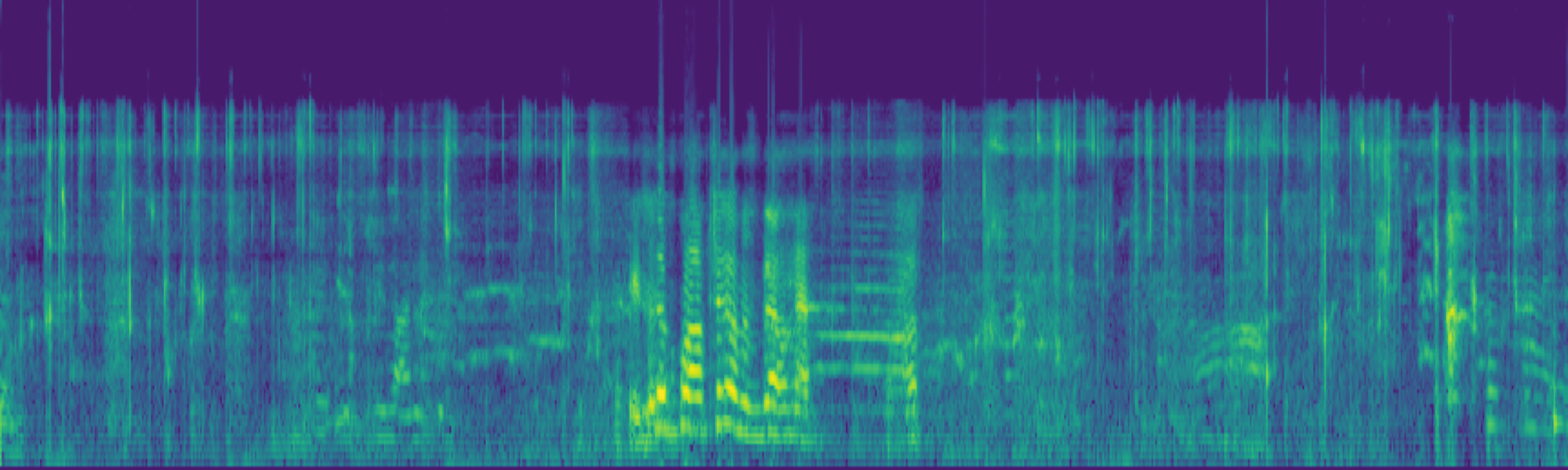
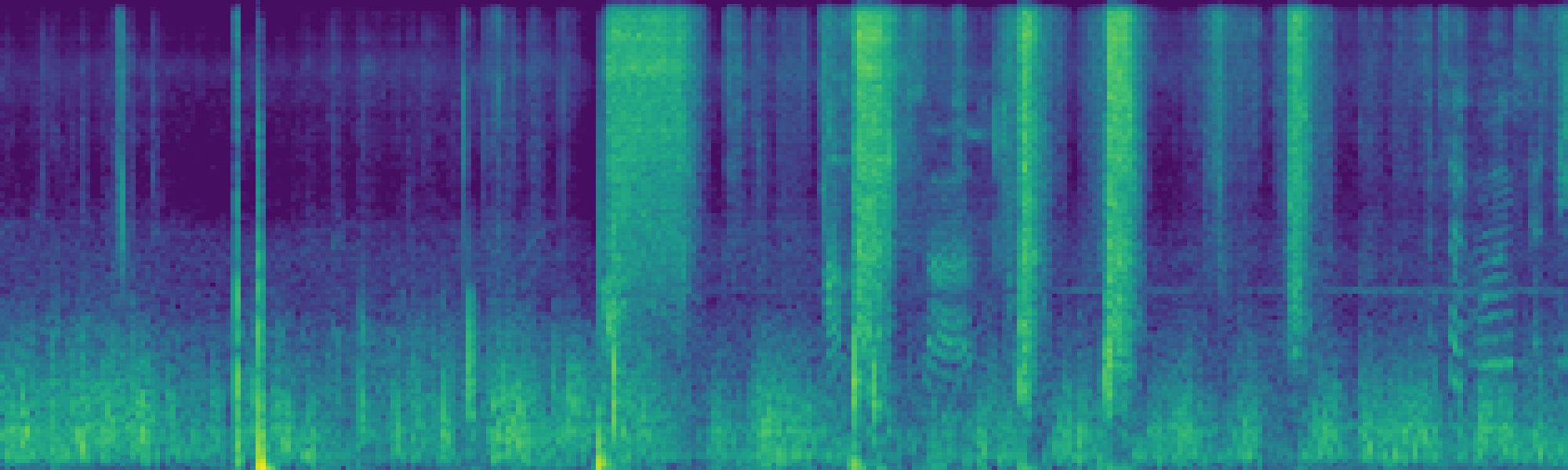
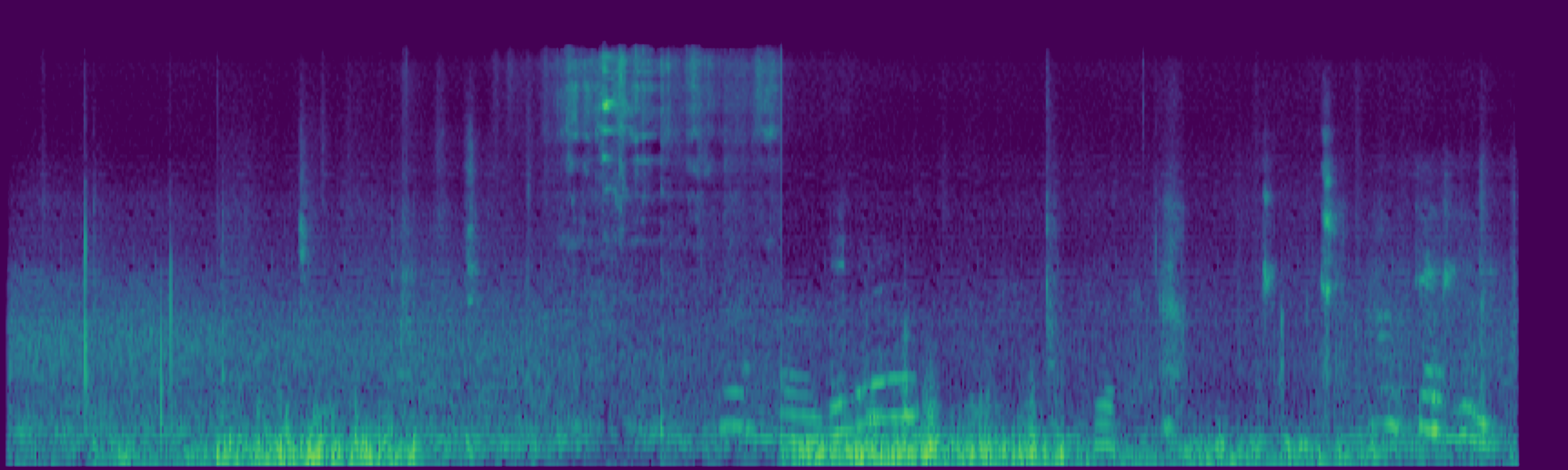
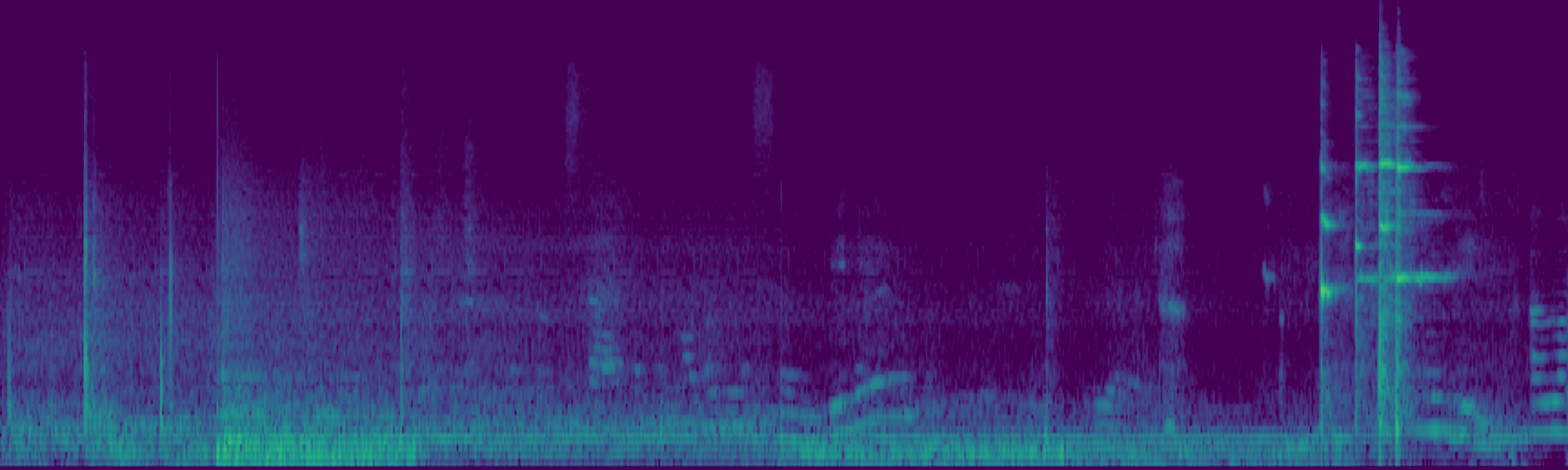
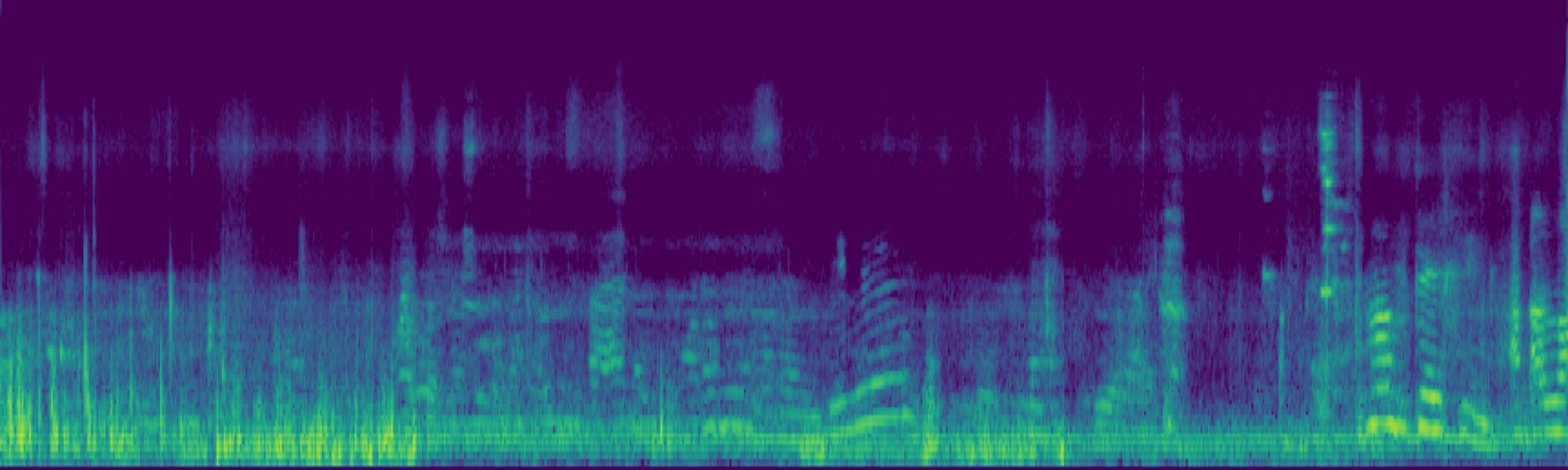
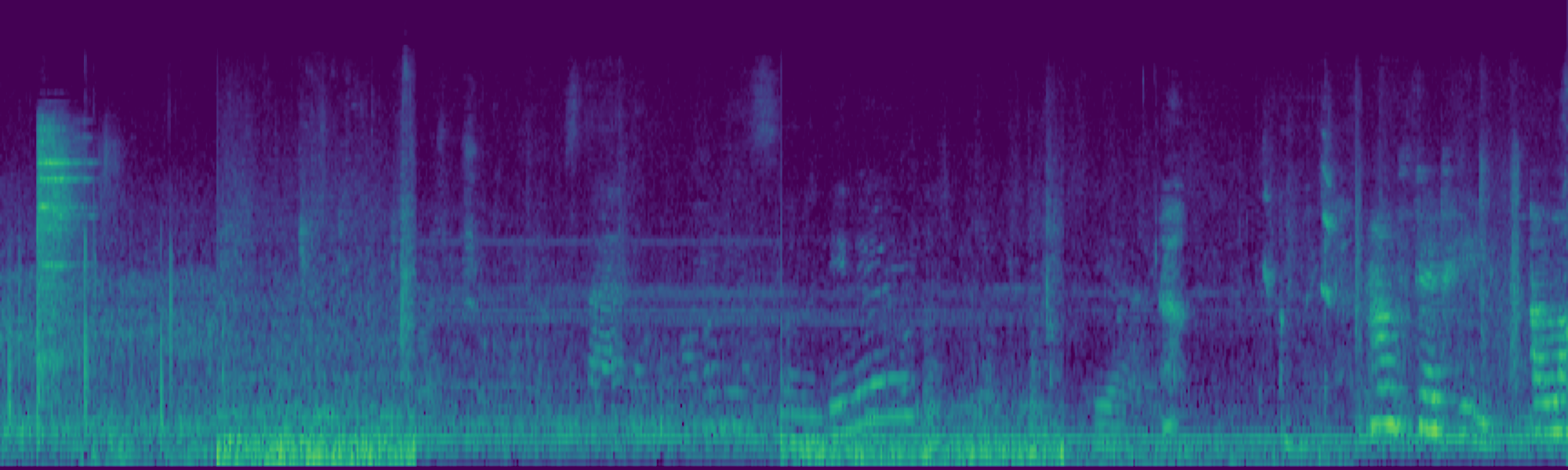
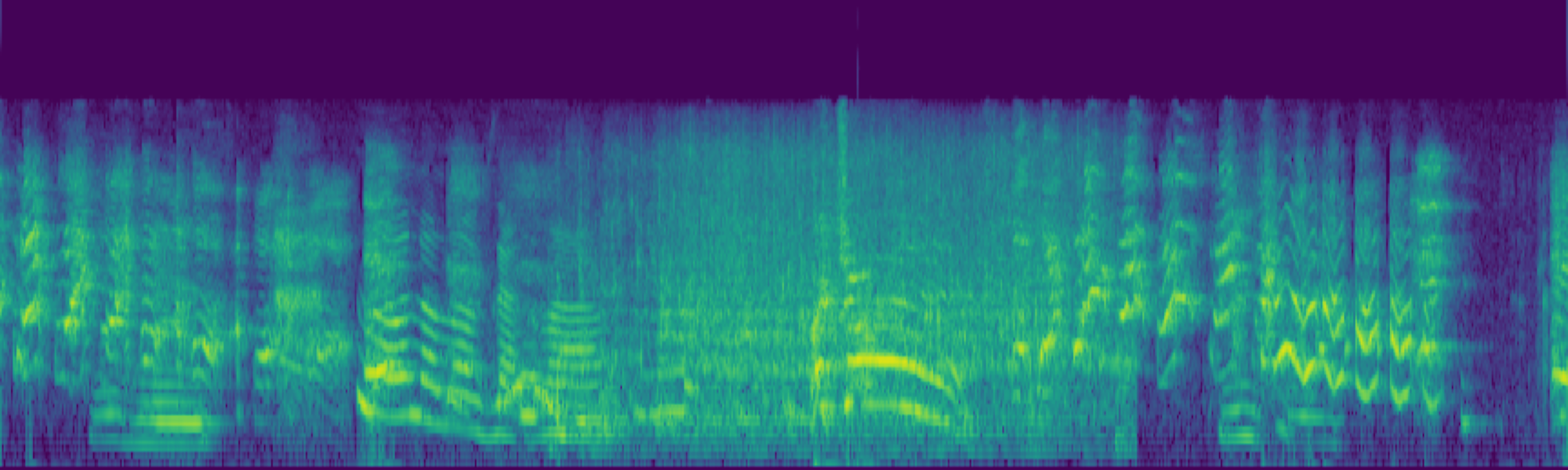
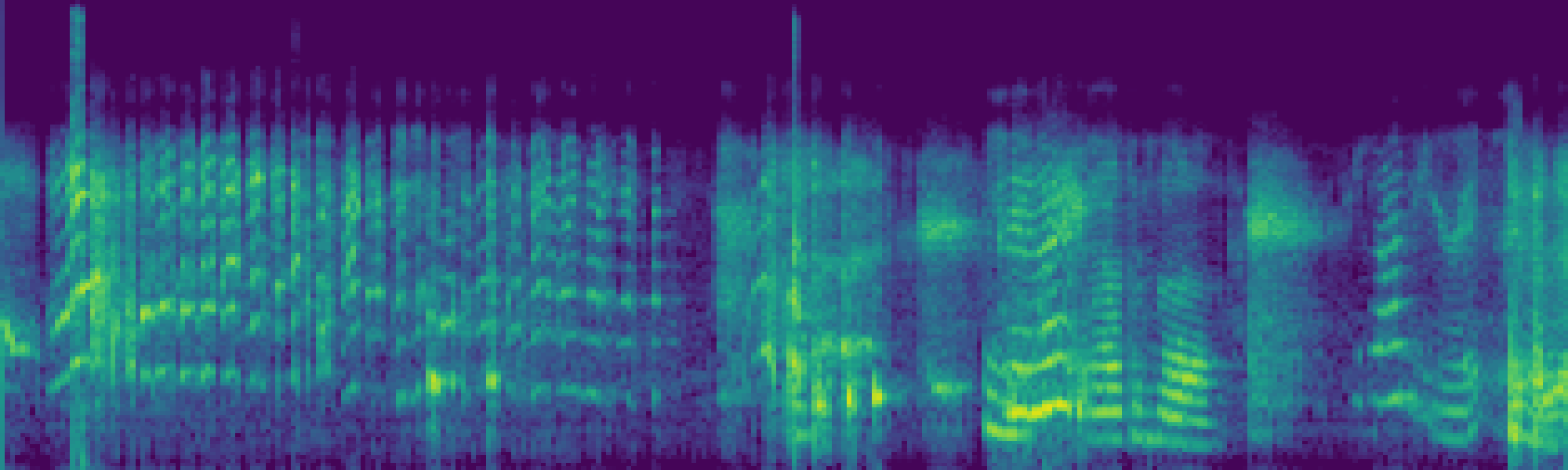
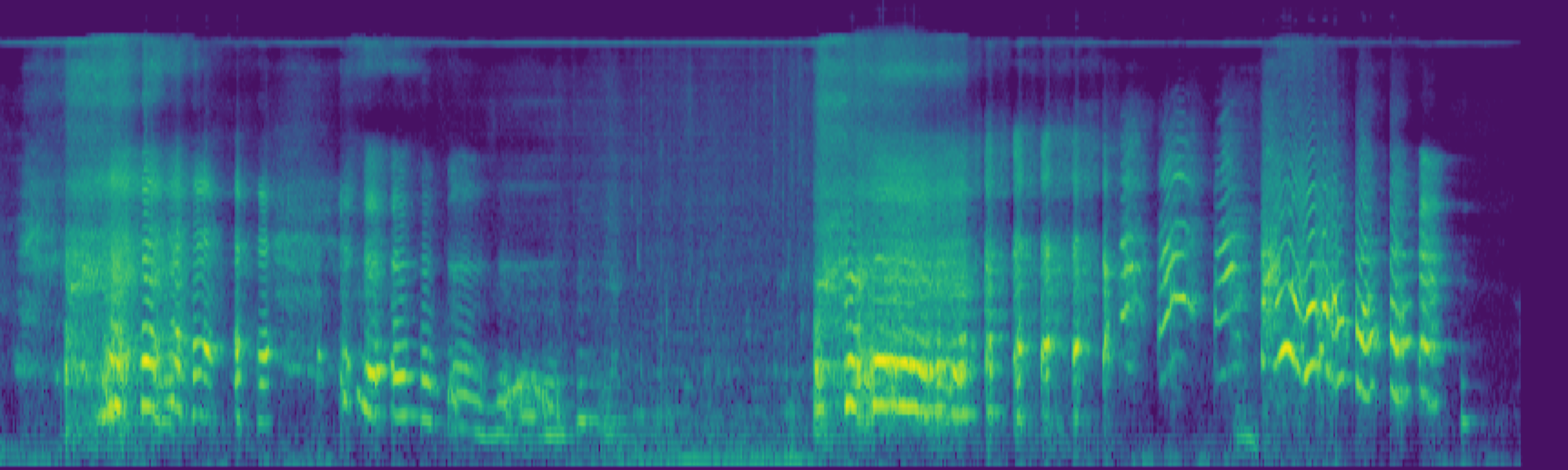
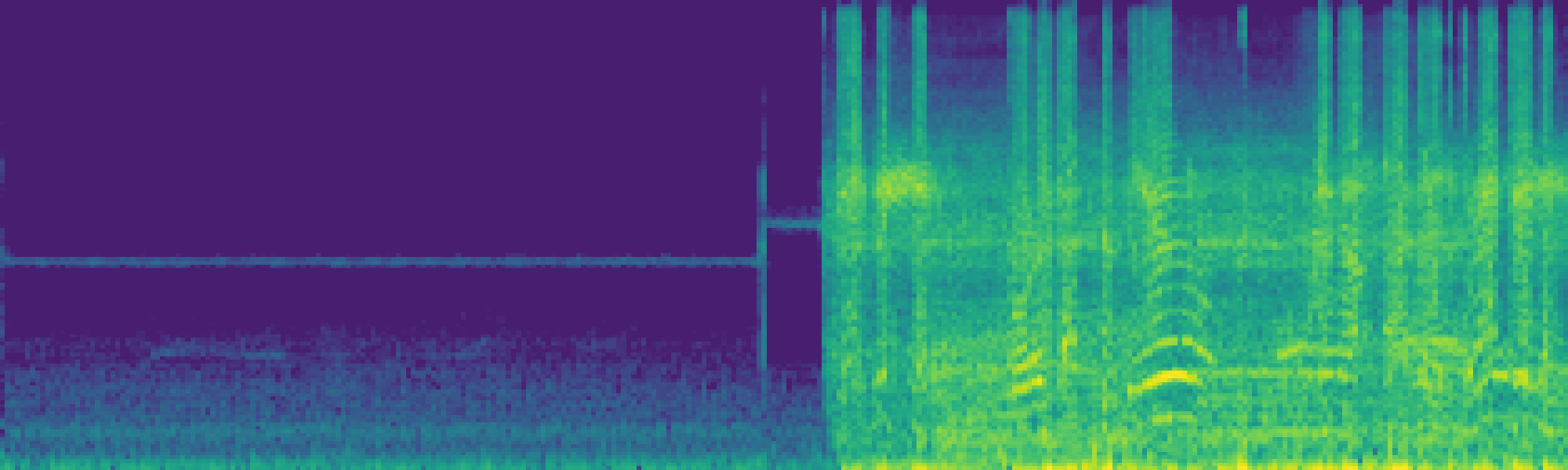
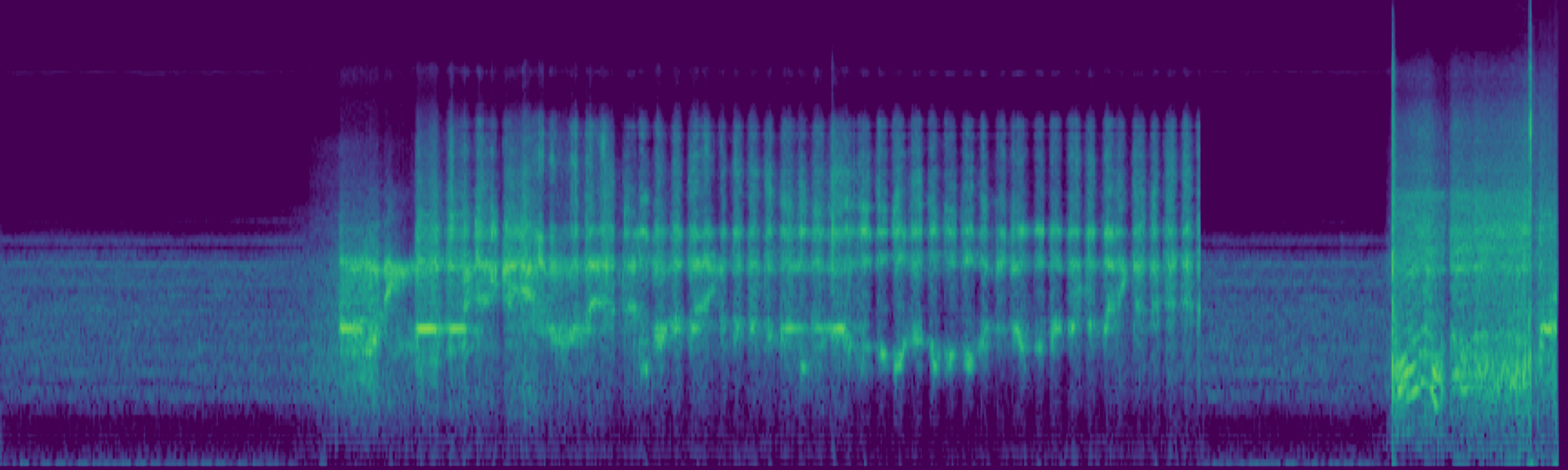
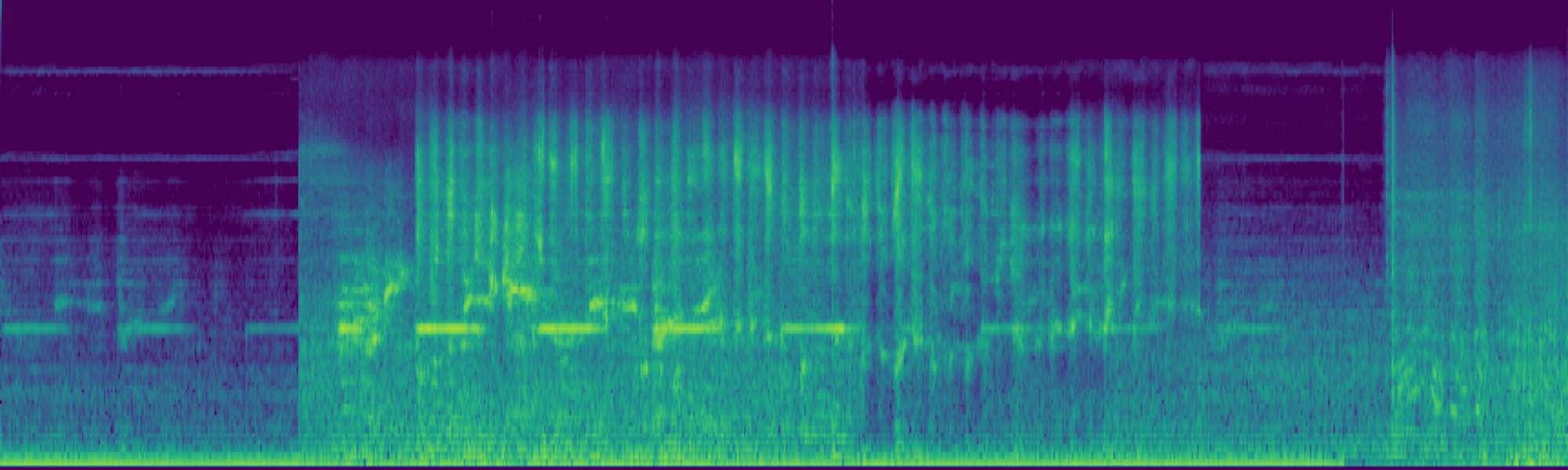
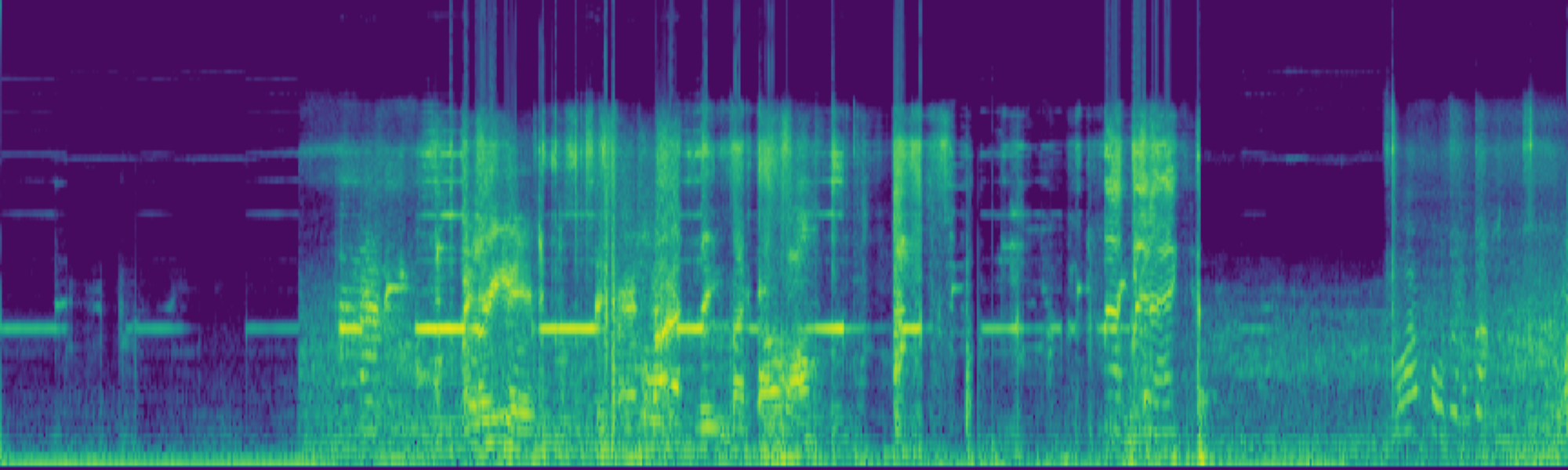
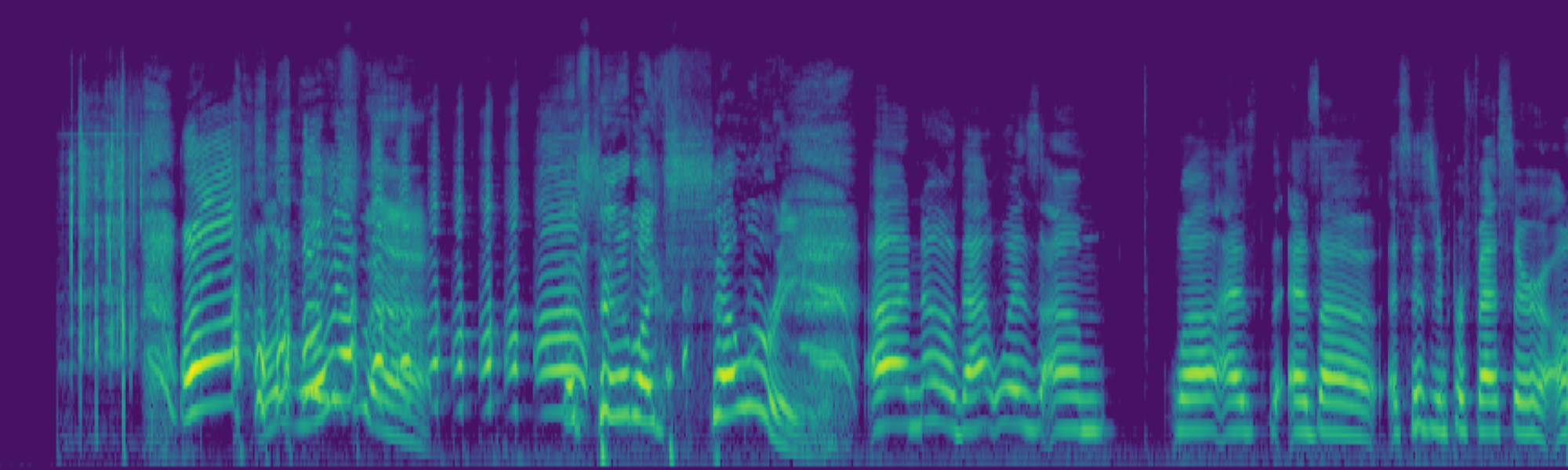
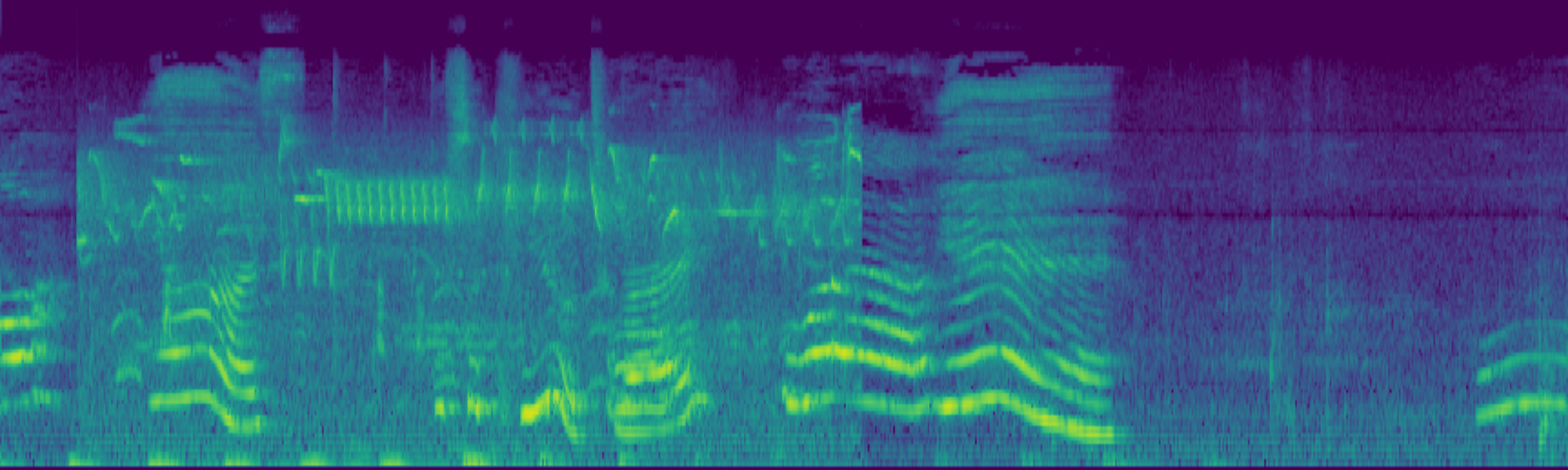
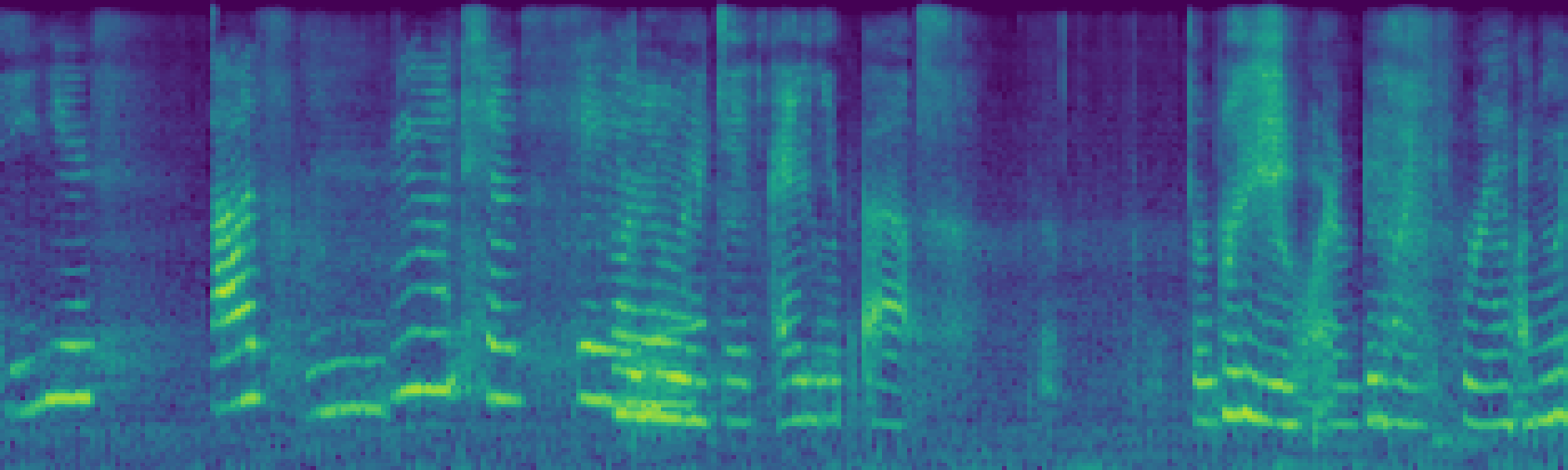
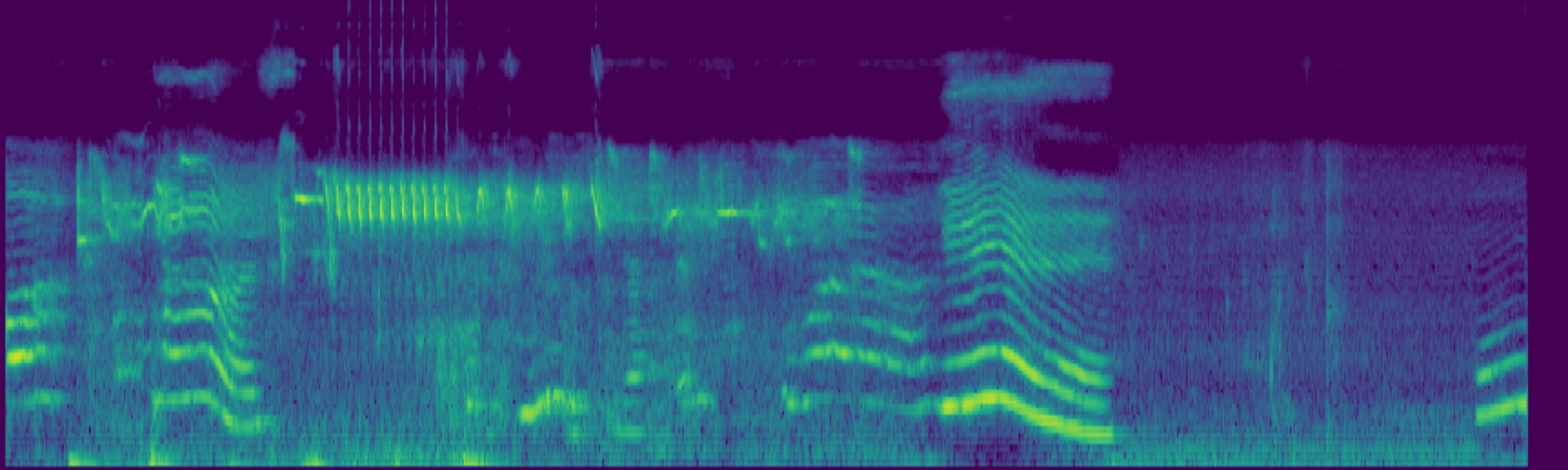
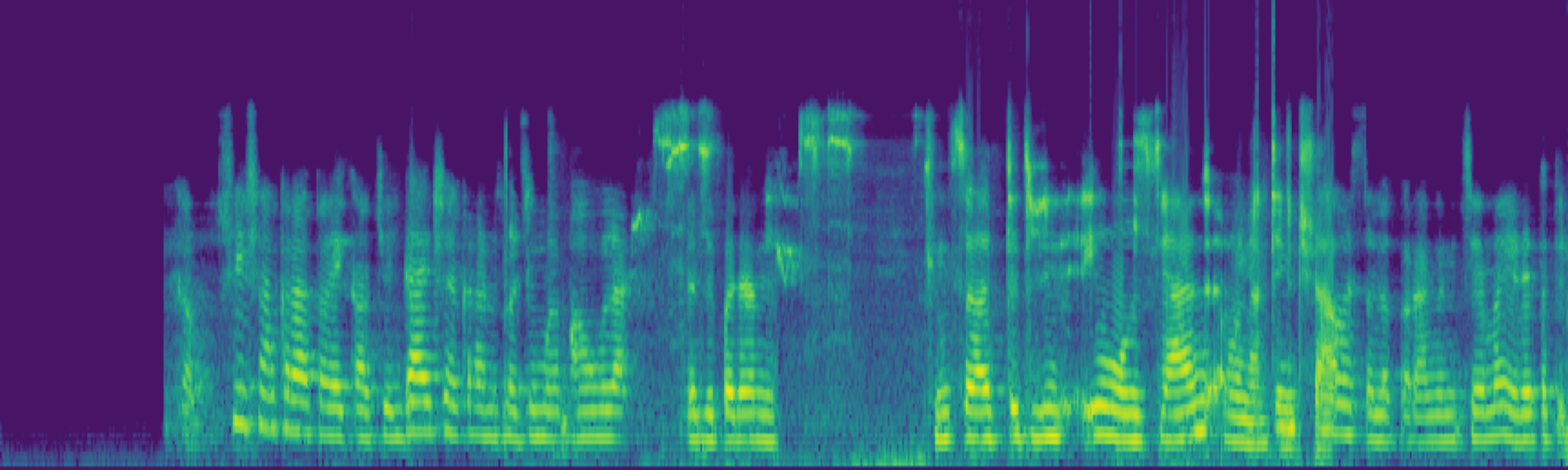
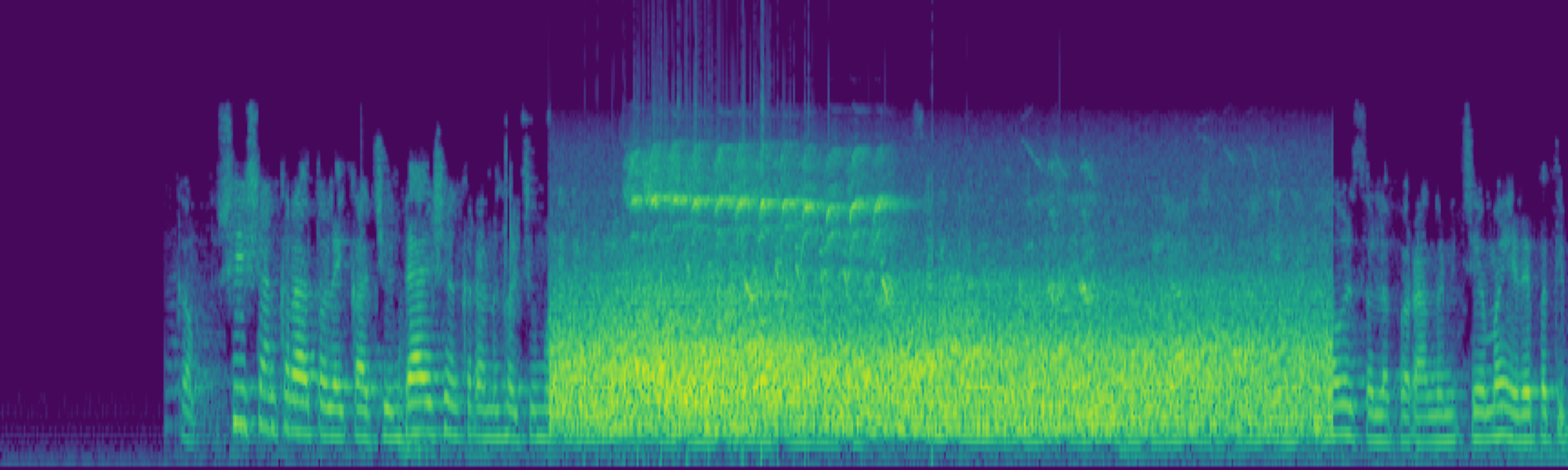
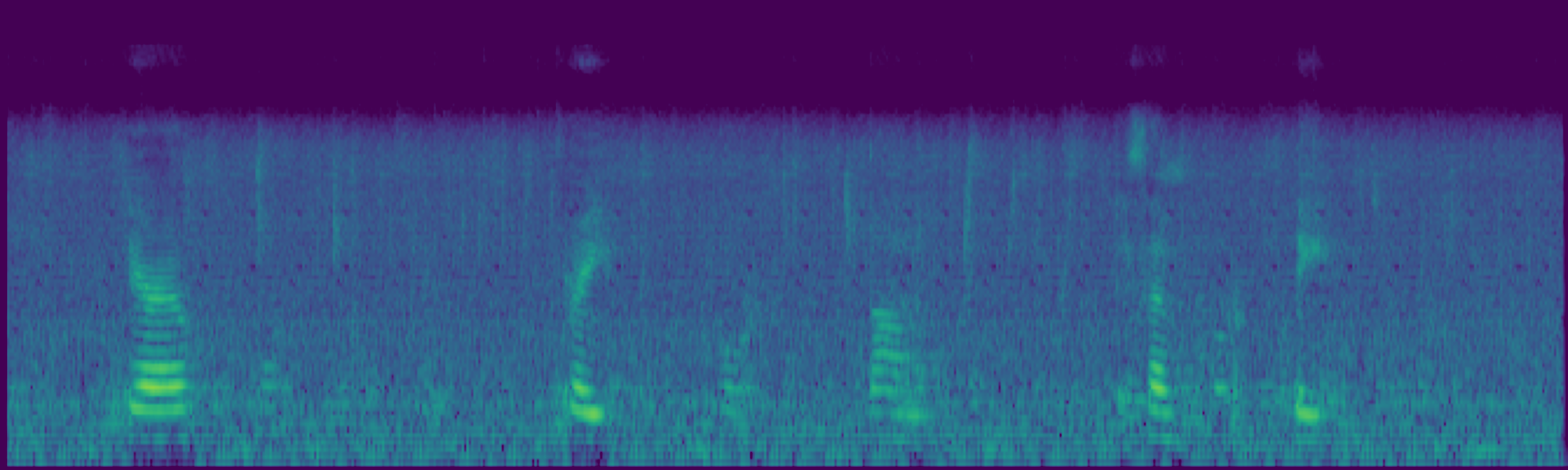
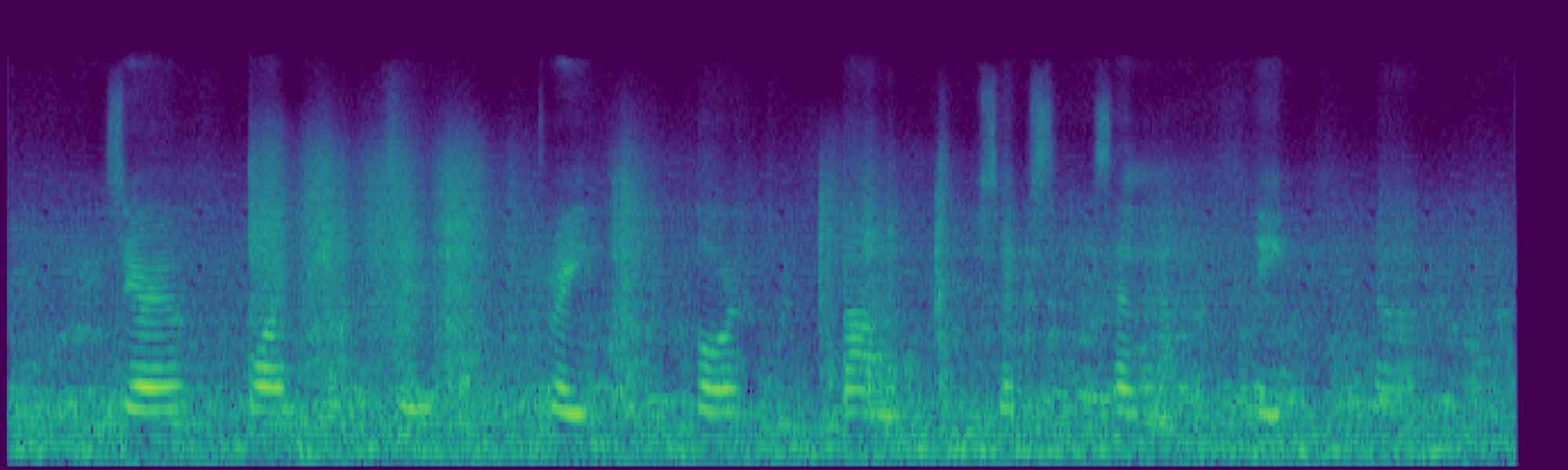
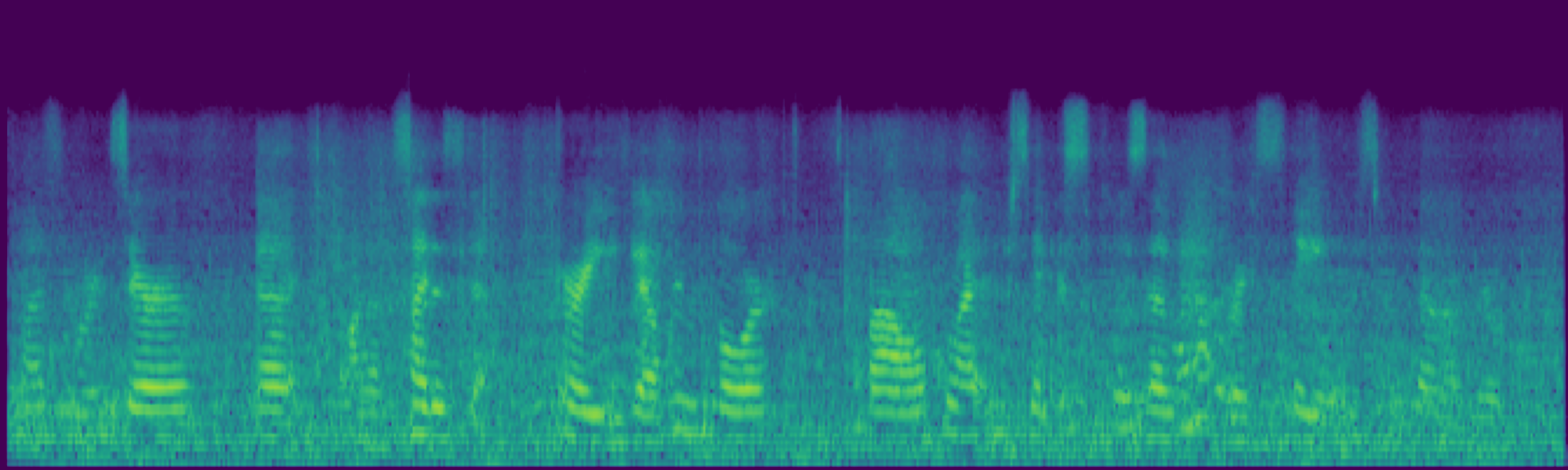
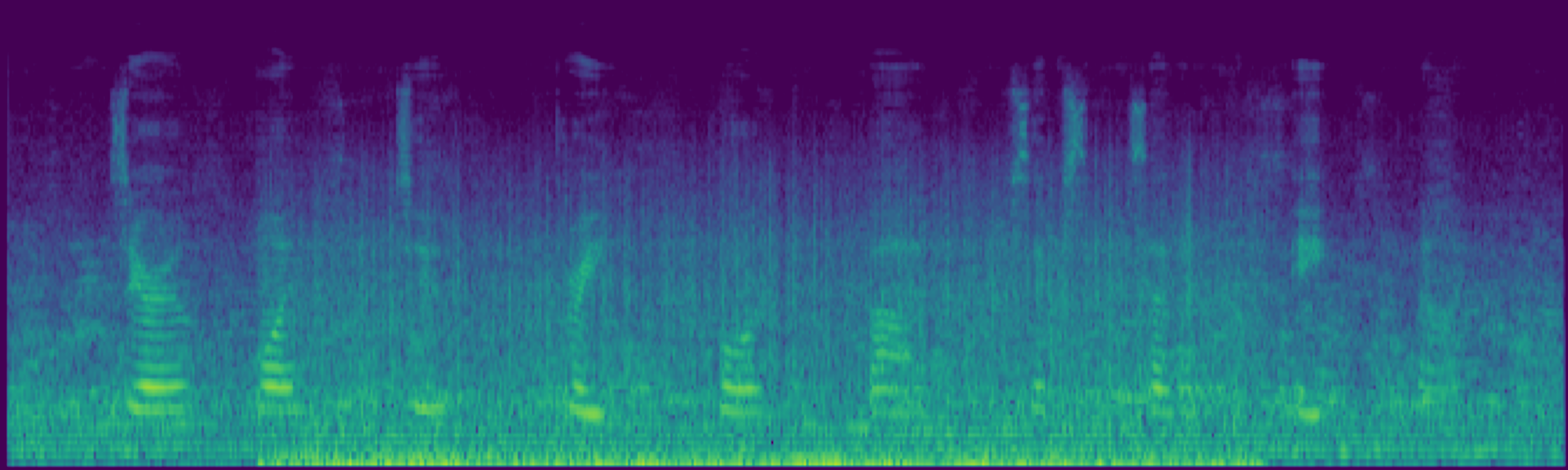
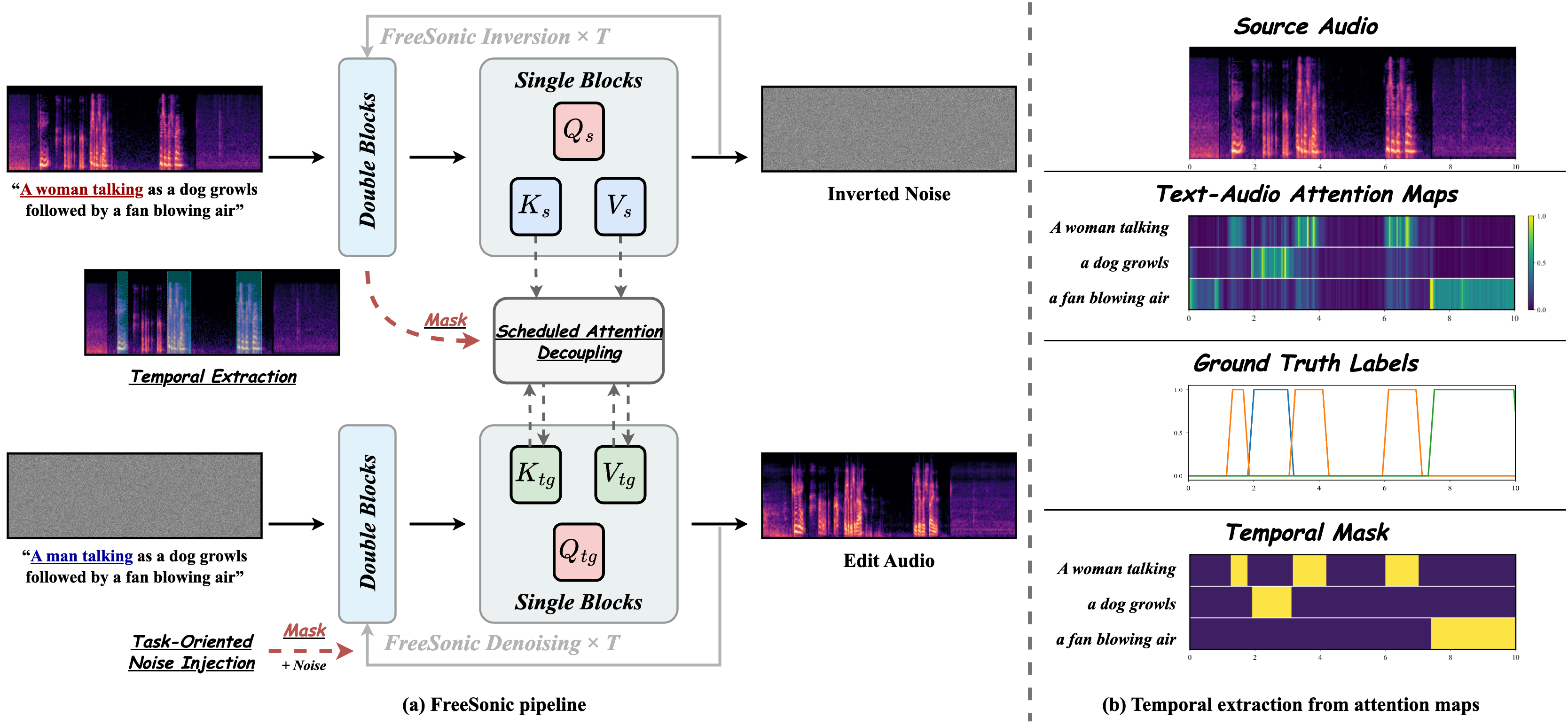
We propose FreeSonic, a training-free audio editing framework built on the Rectified Flow-based TangoFlux model. FreeSonic leverages an optimized inversion-reverse process and utilizes text-audio attention maps for precise temporal localization of target segments. For content modification, it implements a schedule-based fusion of Key and Value (KV) features within the model's internal attention layers, ensuring edits are strictly confined to intended regions while keeping the rest of the audio undisturbed. Additionally, a task-oriented noise injection strategy is introduced to enhance versatility across diverse editing objectives, such as sound removal and semantic substitution.
Experimental results demonstrate that FreeSonic achieves superior performance in maintaining original acoustic integrity while ensuring faithful edits, offering unique flexibility for complex, real-world audio scenarios.
Key Contributions
Training-free editing on Rectified Flow. Built on TangoFlux with an optimized inversion-reverse process, FreeSonic edits audio without any task-specific training or fine-tuning.
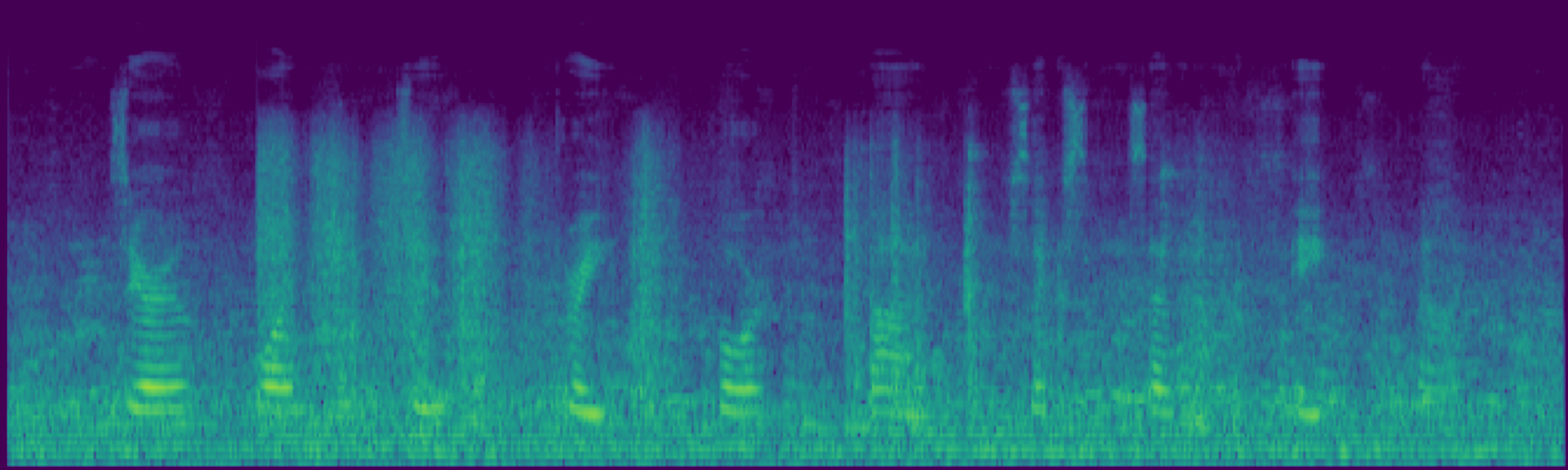
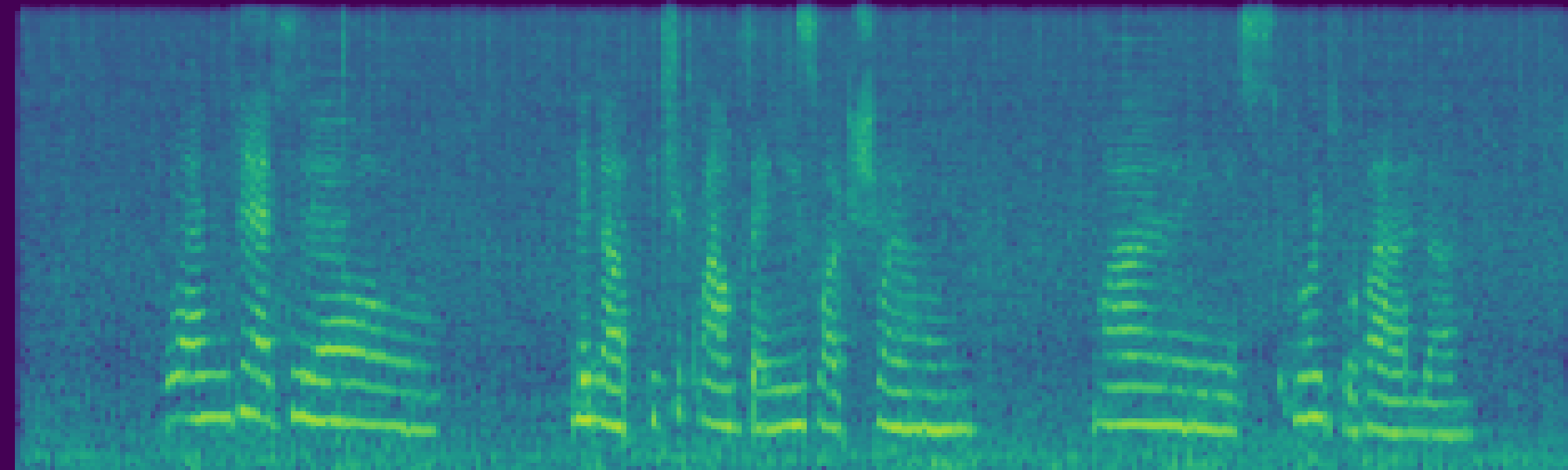
Attention-based temporal localization. Target segments are localized from text-audio attention maps during the first inversion steps, guiding edits to the intended time interval.
Scheduled Attention Decoupling. A schedule-based fusion of Key and Value features inside the attention layers confines modifications to the target region while preserving the background.
Task-oriented noise injection. A unified strategy that adapts to diverse objectives — addition, removal, and semantic substitution — within a single framework.